默认的存储是 NFS,部署在 rbd-system 命名空间下,即 nfs-provisioner-0
nfs-provisioner-0
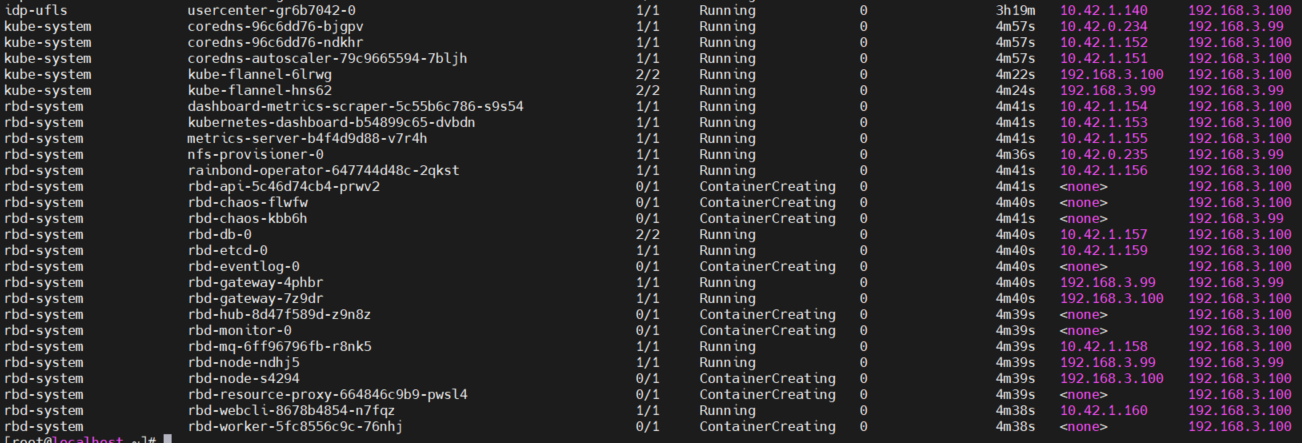
POD 为 ContainerCreating 状态和 df -h 卡住都是同一个问题,存储挂不上。
df -h
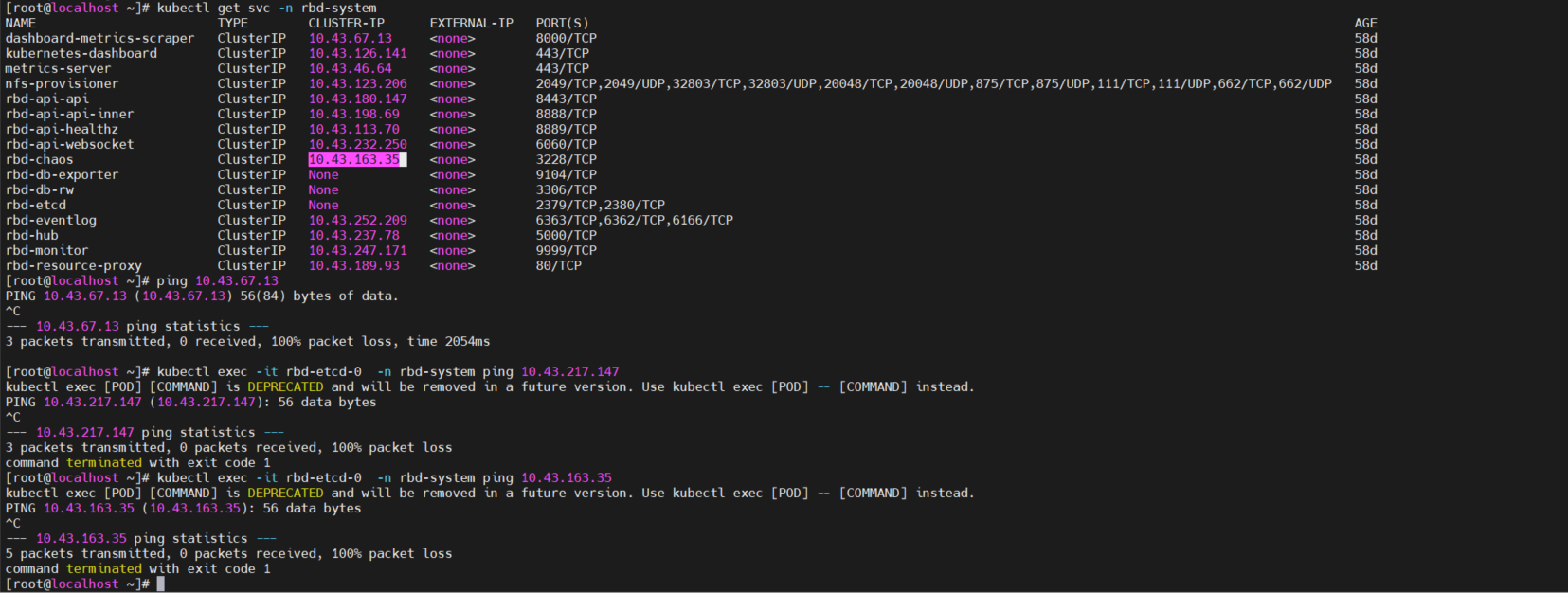
存储挂载 IP 地址是 nfs-provisioner 的 Service IP kubectl get svc nfs-provisioner -n rbd-system,挂载不上说明 Service IP 不通,这通常是跨节点 Service 通信出现的问题,可以从这个方向排查 kube-proxy 和网络插件的问题
kubectl get svc nfs-provisioner -n rbd-system
kube-proxy
我用pod去ping svc的ip好像都是不通的。
有一个不是很理解的地方就是,rainbond上面部署的一些应用,这些应用里有挂载存储的,这些应用好像就能挂载上。kube-proxy 我这边没有看到这个组件。
我看两个网络插件日志里也没有什么报错信息。
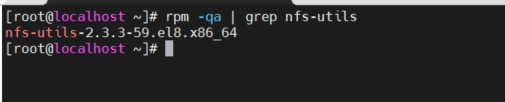
还有一个就是我发现nfs-provisioner 里 nfs-utils 版本和两个主机的版本不一致 nfs-provisioner 宿主机上的
我在宿主机上想挂载好像也不行,会不会是两个nfs版本不一致的问题
应用现在已经无法使用存储了,现在处于假死状态
手动挂载的这个命令的IP就是 Service IP,挂不上说明 IP 不通,就是 Service IP 不通。
还是要从 kube-proxy 方向排查
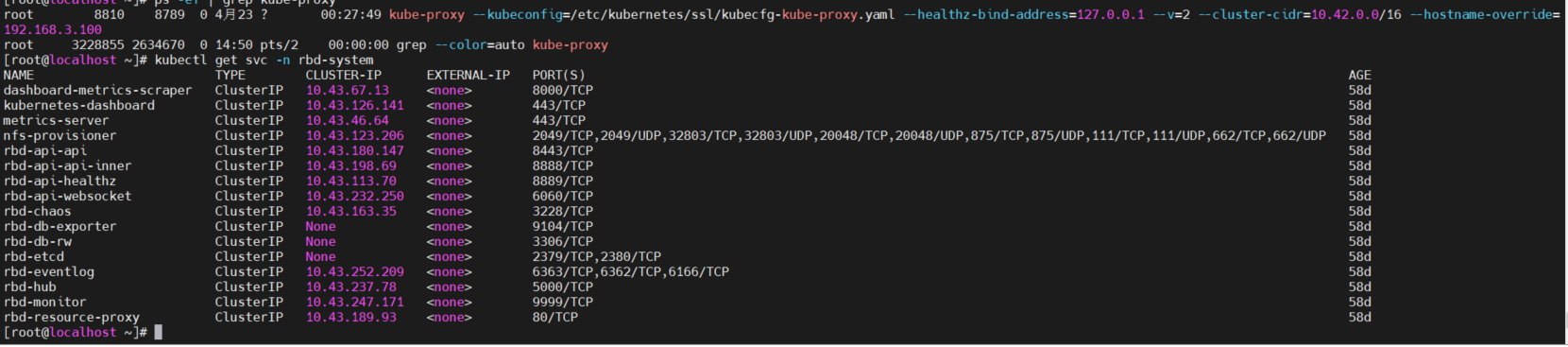
这个kube-proxy我这边没有找到这个pod ,是kube-fannel吗
感觉这个kube-proxy指定的cluster-cidr ip和svc里的cluster-ip不一致
这个kube-controller-manager的service-cluster-ip配置的是有问题的。我想问一下这个我想改正确之后,再重启这个要怎么做呢
1456944262 你的k8s集群怎么搭建的,是通过 Rainbond 搭建的么?
是的
1456944262
尝试重启所有节点的 kube-proxy
docker restart kube-proxy
如果是 centos 系统,需关闭 NetworkManager 服务,然后重启服务器
NetworkManager
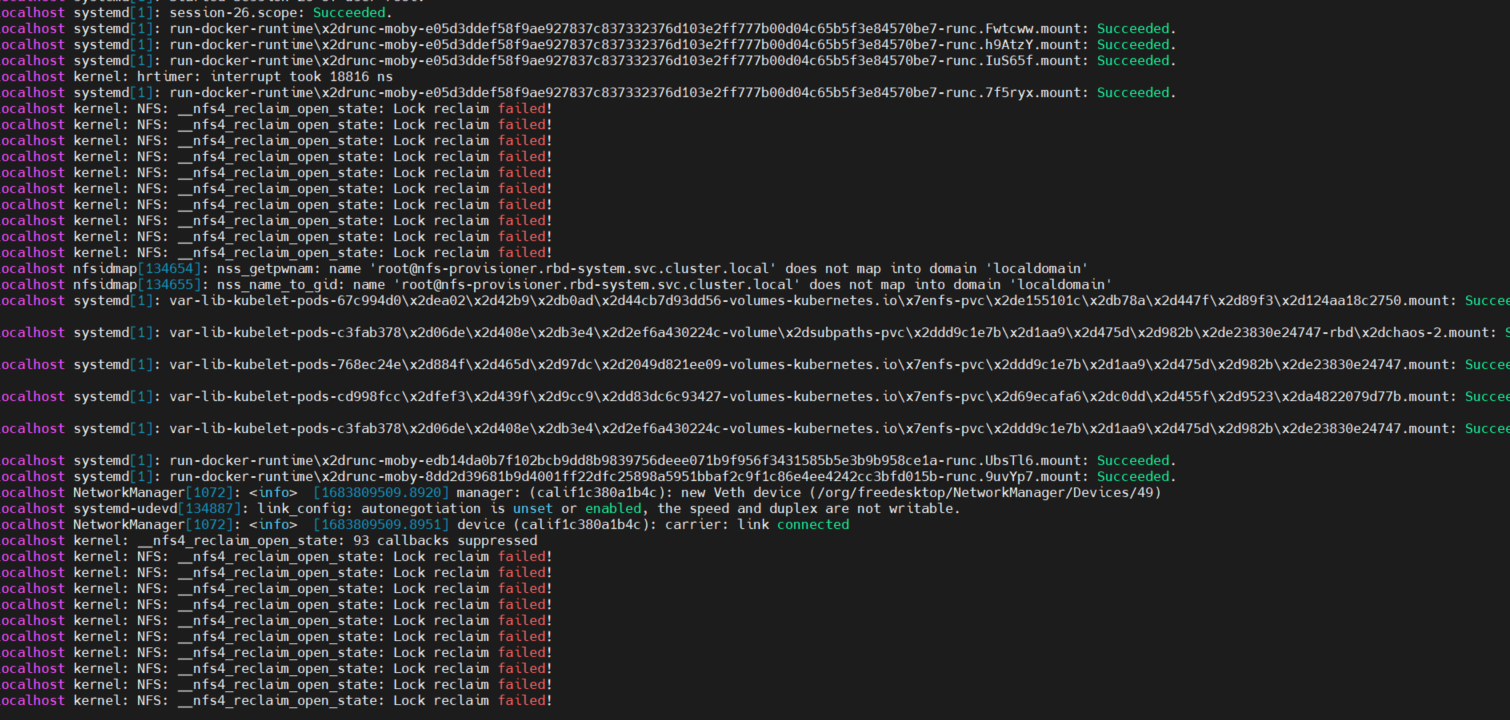
我这边今天在一台新的机器上装了一次集群,看这个ip应该时对的,然后我这边重启完服务器情况还是一样的,还是会卡,只要df -h 一卡 ,api组件就unready了,就挂载不上了,这个会不会时nfs 软件性能的问题, 我看系统日志一直在刷这个,而且我看nfs-provisionr-0里版本和服务器上的不一样 pod里的 服务器上的
看报错是不支持 NFS 文件锁,可以看看这个文章,https://www.infoq.cn/article/UKKgaMSuBywDVWwCrbrN
SmallQi 想了解一下这个不支持nfs会导致挂载不上吗,这个我看我服务器重启之后一小会是正常的,然后就开始了api就挂了,感觉随着时间推移这个挂的越来越快,这个我可以从5.11.0直接升级到5.12.0吗,跳过5.11.1
不支持肯定不行。可以夸版本升级,参考文档:https://www.rainbond.com/docs/upgrade/latest-version
最终怎么解决的呢