我们在实际搭建中推荐使用的是GlusterFS复制集,故在此介绍GlusterFS复制集的相关内容。更多卷类型请参阅 GlusterFS官方文档
一. GlusterFS复制集原理
架构图
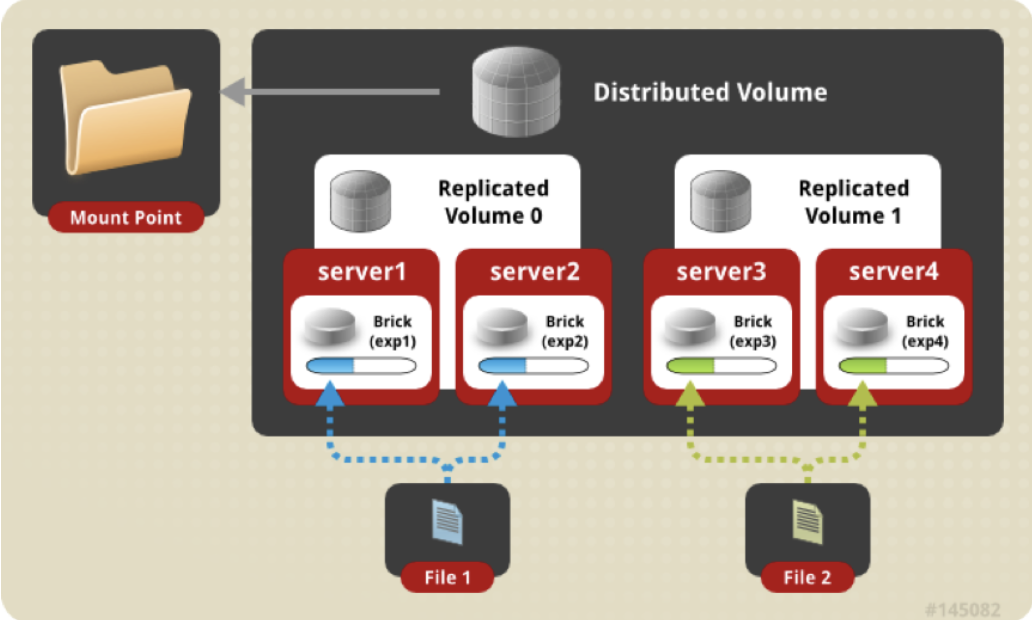
Brick server 数量是镜像数的倍数,可以在 2 个或多个节点之间复制数据。分布式的复制卷,volume 中 brick 所包含的存储服务器数必须是 replica 的倍数(>=2倍),兼顾分布式和复制式的功能。
常见术语
| 名称 | 解释 |
|---|
| Brick | 最基本的存储单元,表示为trusted storage pool中输出的目录,供客户端挂载用 |
| Volume | 一个卷,在逻辑上由N个bricks组成 |
| FUSE | Unix-like OS上的可动态加载的模块,允许用户不用修改内核即可创建自己的文件系统 |
| Glusterd | Gluster management daemon,要在trusted storage pool中所有的服务器上运行 |
| POSIX | 一个标准,GlusterFS兼容 |
二. GlusterFS脑裂解析
所谓脑裂,就是指两个或多个节点都“认为”自身是正常节点而互相“指责”对方,导致不能选取正确的节点进行接管或修复,导致脑裂状态。这种现象出现在数据修复、集群管理等等高可用场景,详情参阅官方文档
产生原因
- 网络原因
(1)有一个由2个卷组成的副本对,包括server1上的brick1和server2上的brick2;
(2)由于网络断开,client1失去了与brick2的连接,而client2失去了与brick1的连接;
(3)此时从client1将数据写入卷1,从client2将数据写入卷2,网络恢复之后,两个节点数据不一致,这将会产生脑裂。
- GlusterFS的进程出现问题
假设现在有两个节点的集群server1和server2。
(1)server1挂了,此时文件的操作时发生在server2上;
(2)server1启动,server2挂掉了,此时文件的操作时发生在server1上;
(3)server1和server2都启动了,此时两个节点上的副本就会不一样。
预防脑裂
在搭建GlusterFS复制集时,如果副本数设置为2,可能会有脑裂(Split-brain)的风险(在创建时会风险提示,但可配置),主要原因是在两个副本不一致时,无法仲裁以哪个副本为准,解决方案是加入仲裁或者设置3副本;所以在安装部署时推荐部署3副本的复制集,以规避后期数据迁移所带来的风险。
副本升级实践
以下是将原有GlusterFS复制集2副本升级至3副本的实践
注意:进行以下操作时请勿在平台上进行操作,以免造成数据不一致
管理节点需要先停服务
grclis stop
将现有数据进行备份
rsync -azvtP /grdata /rain/
卸载之前的挂载
umount /grdata
停止并删除原数据卷
gluster volume stop data
gluster volume delete data
# 创建3副本卷
[root@ ~]#: gluster volume create raindata replica 3 <主机1>:/data/glusterfs <主机2>:/data/glusterfs <主机3>:/data/glusterfs <主机4>:/data/glusterfs <主机5>:/data/glusterfs <主机6>:/data/glusterfs
volume create: data: success: please start the volume to access data
# 启动volum
gluster volume start raindata
# 查看卷信息
[root@ ~]#: gluster volume info
客户端更换挂载点
vi /etc/fstab
主机1:/raindata /grdata glusterfs backupvolfile-server=主机2,use-readd irp=no,log-level=WARNING,log-file=/var/log/gluster.log 0 0
# 重新挂载
mount -a
同步数据至新的复制卷
rsync -azvtP /rain/grdata /grdata
其他节点,修改/etc/fstab重新挂载/grdata
迁移完成确定集群状态
grctl cluster
最后在平台验证服务是否正常
三. Glusterfs运维
3.1 维护常用操作
| 卷的常用操作 | 命令 |
|---|
| 创建卷 | gluster volume create |
| 启动卷 | gluster volume start |
| 停止卷 | gluster volume stop |
| 删除卷 | gluster volume delete |
| 添加节点 | gluster peer probe |
| 删除节点 | gluster peer detach |
| 列出集群中的所有卷 | gluster volume list |
| 查看集群中的卷信息 | gluster volume info |
| 查看集群中的卷状态 | gluster volume status |
3.2 常用命令
磁盘平衡
# 开始平衡
gluster volume rebalance VOLNAME start
# 查看平衡状态
gluster volume rebalance VOLNAME status
# 停止平衡
gluster volume rebalance VOLNAME stop
脑裂相关
# 查看脑裂信息
gluster volume heal VOLNAME info split-brain
# 开启目录索引的自动愈合进程
gluster volume set arch-img cluster.self-heal-daemon on
# 自动愈合的检测间隔,默认为600s (3.4.2版本之后才有)
gluster volume set arch-img cluster.heal-timeout 300
3.3 常用优化参数
| 配置选项 | 用途 | 默认值 | 合法值 |
|---|
| network.ping-timeout | 客户端等待检查服务器是否响应的持续时间,节点挂了数据不能写入 | 42 | 0-42 |
| Performance.cache-refresh-timeout | 缓存校验周期 | 1s | 0-61 |
| auth.allow | 允许访问卷的客户端ip |
| auth.reject | 拒接访问卷的客户端ip |
| performance.cache-size | 读取缓存的大小 | 32 MB |
| performance.write-behind-window-size | 能提高写性能单个文件后写缓冲区的大小 | 1MB |
| performance.io-thread-count | IO操作的最大线程 | 16 | 0-65 |
更多官方参数
gluster volume set <VOLNAME>
GlusterFS集群会有一个检测时间默认是42s,如果一个节点挂了或网络不通了,整个集群都会在这42秒内无法写入数据,所以通常会修改这个检测时间;在此我们将他改为10s。
[root@server1 ~]# gluster volume set data network.ping-timeout 10
volume set: success
3.4 系统配额
1、开启/关闭系统配额
gluster volume quota VOLNAME enable/disable
2、设置(重置)目录配额
gluster volume quota VOLNAME limit-usage /img limit-value
gluster volume quota img limit-usage /quota 10GB
设置img 卷下的quota 子目录的限额为10GB。这个目录是以系统挂载目录为根目录”/”,所以/quota 即客户端挂载目录下的子目录quota
配额查看
gluster volume quota VOLNAME list
使用以上命令进行系统卷的配额查看,查看目的卷的所有配额设置,可以显示配额大小及当前使用容量,若无使用容量(最小0KB)则说明设置的目录可能是错误的(不存在)。
3.5 版本升级
Ubuntu系统GlusterFS升级
apt install -y software-properties-common
add-apt-repository ppa:gluster/glusterfs-7
apt-get update
killall glusterfs
systemctl stop glustereventsd
apt-get -y install glusterfs-server